So this post is kind of off-topic, and yet, as you will see later on, knowing how WCC works actually solved a problem I had with ADF and JDeveloper 12.2.1.3.
So, consider you want to build an ADF application but you do not want to install a full Oracle DB to run on. I can think of plenty of reasons why I would want to do this, like the fact that MySQL requires far less system resources to run.
Everything seems to work just fine, except when you start building queries with bind variables.
ADF will try to assist you in every step of your development. So there are wizards to create the entities for your tables in the DB, and wizards to create the view object you will use in your code.
Say you want to have a view that is based on a query with a parameter that come from a form or whatever.
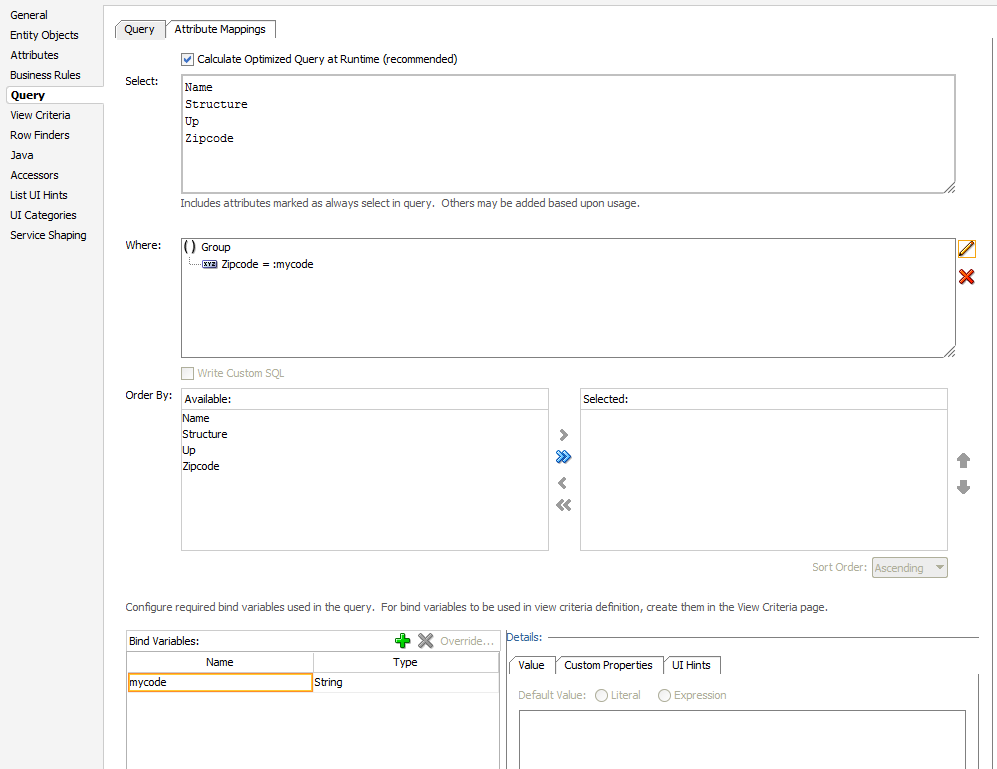
Consider the following example: A simple view with postal codes.

Now we want to edit the query to just show all the records that have the same zipcode. So what you do is hit the edit button next to the query window, and add your clause.
You start by adding a condition:

And you add the bind variable that you want to use. Basically you can choose any name here as long as to correctly assign it later when you want to use this view.

As a result, you now have a view with a where clause. And if you are working with an Oracle database this will work just perfectly.
However we are using MySQL.....
For me, there was no way I could get this to work with MySQL. No even the BC4J Tester will come up. Setting logging on BC4J you find that you are running into the following error:
java.sql.SQLException: Parameter index out of range (2 > number of parameters, which is 1).

I searched all over the internet, and maybe it was due to how I searched but it took me for ever to find any relevant information that could explain the error. It seems that the problem is the way JDeveloper creates the where clause:

Somehow this is not compatible with MySQL... But why is that?
Well as it turns out, the MySQL drivers (and I tried several versions) have an issue with the way Jdev defines the bind variable. The mention about the index position in the error made me think about how queries are defined in WCC, and that got me started on the road to the solution.
I basically edited the query to the syntax that you will find in the query.htm file of Content Server. In Content server, bind variables are represented by question marks and there is a list of bind values in correct sequence.
So what I did is the following:
- Go to manual mode: deselect the "Calculate Optimized Query at runtime" option.
- Now you can manually edit the where clause. This is what it said before

- And this is what I changed it to:

- One last step you need to you is change the properties of the bind variable

- Make sure that you set the bind position correctly. If you have multiple bind variables just enter the correct sequence. 0 stands for the first question mark in the statements, etc.



Once you have done this, it is time to test once again.
Now BC4J tester launches without problems, you can open the view, you get prompted for a value of the bind variable and you get the corresponding filters records.


So strange enough, knowing WebCenter Content, helped me to solve something completely unrelated.
Hopefully this can be useful for somebody, bye for now....